
Building a multi-GPU Hashcat password cracking cluster can be very economical if you choose a combination of budget GPUs with a reasonable hash rate.
Nowadays, due to the AI craze and before that due to the cryptocurrency craze, there has been a serious price inflation and price gouging by GPU vendors, such as NVIDIA, for graphics cards that can perform a lot of password cracking at scale.
In this post, I show you how to build a multi-GPU cluster and achieve a better price/performance ratio with several budget GPUs as compared to buying one expensive one.
The goal for my use case is to optimize on both price and risk. There is a risk that if you run a lot of password hash cracking on a GPU, that it may wear out earlier. When you use budget GPUs, you may wear them out but they are cheaper to replace, and hence, cost effective.
Except for the GPUs, and their PCI-E risers, everything else I bought pre-owned on online marketplaces, since you don’t need some parts to be new.
I used 5 GPUs for this cluster, and a 6th one can be added to it. This is a self-contained cluster and you do not need a monitor as I use an HDMI screen as part of it.
NOTE: This cluster can be used for machine learning and other CUDA programming too!
REQUIREMENTS
- 5-6 GPUs NVIDIA GeForce 1650 GTX - Amazon Link, Best Buy Link. I purchased these on sale each for $139.99 during Labor Day and Thanksgiving sales in the USA. So my total cost was less than $900 including taxes, which is cheaper than a new RTX 4090 GPU which can be over $1600. Although the RTX 4090 can provide insane performance, if you can afford it.
- Refurbished HP Z840 with 128GB RAM and 1 TB SSD hard drives from eBay for about $460. You can use any other barebones PC, but it does help to have at least 32 GB RAM and 6+ GPU slots. Cryptocurrency miners use motherboards that have 12 GPU slots but you do not get enough RAM or powerful CPUs in those, so the multipurpose nature of your cluster to run machine learning and/or password cracking may not be possible.
- Kali Linux or Ubuntu 22.04 LTS
- NVIDIA drivers. I am running
NVIDIA-Linux-x86_64-535.146.02.runfrom NVIDIA for Linux. - 6 GPU Risers. These are needed to allow the variety of PCI-E slots to be used with the PCI-E x16 GPUs.
- Crypto mining rig hardware or a pre-owned rig from Facebook Marketplace. I bought mine for $30 along with all the fans, which I did not use.
- EVGA 1500W Power Supply or a pre-owned one that works. I bought mine pre-owned for $40.
- Extruded Aluminum if you want to DIY the whole structure from scratch.
- Aluminum rail accessories. You will need this for attaching some of the rig parts together, if your rig is like mine.
- Brass Standoff screws for attaching the GPUs to the rails.
- Tap and Die Set for threading the small holes required for your standoff screws
- Drill and drill bits. I already had these and do not count this towards the budget. You can procure the drill on Facebook Marketplace for cheap, and buy new drill bits.
- HDMI 7” screen for using as a touch screen monitor.
- Metric Allen wrench set
- Phillips Screwdriver, Pliers
All in all, with the mix of new and pre-owned equipment, I spent about $1550. If you were to buy everything new, you may end up paying about $500 more, which could be instead leveraged to buy more GPUs. Or you can buy an RTX 4090 and not need anything above!
SETUP
In Figure 1, you see a typical cryptocurrency miner rig. It has 7 large fans, a big 1500W+ power supply, a space to mount the motherboard (shown highlighted by the yellow rectangle) and a wide beam to screw the GPUs onto. You can see my pre-owned frame has some screws still there near the bottom edge of the yellow rectangle on the beam.
 Figure 1. A typical cryptocurrency miner rig
Figure 1. A typical cryptocurrency miner rig
But before you do anything to the frame, you want to test your hardware out so that you can make sure that you have all the right parts, your risers work and your GPUs work. Figure 2 shows me testing my hardware out. Testing is described in the section here.
 Figure 2. Testing out all the hardware first
Figure 2. Testing out all the hardware first
I disassemble the whole rig into its parts and find the best matching aluminum legs and corresponding screws to create a flat structure like in Figure 3. If you are not using a pre-designed frame, you can use the Extruded Aluminum to DIY the whole structure. You will need to drill holes and use the tap-and-die set to thread the holes for screws, both standoff screws and any other screws that allow you to put the legs together. You can also use the aluminum rail accessories to attach legs to each other.
I also drilled small 1/8” holes for the M3 screws to hold the GPU risers as shown in Figure 3. You can see my brass standoff screws there waiting to hold GPU risers. NOTE: Make sure your measurements are perfect. I used a painters tape on the aluminum legs, marked and then drilled to make sure I did not get positioning wrong.
 Figure 3. Create a new base for the GPU risers
Figure 3. Create a new base for the GPU risers
I then installed all the risers, and screwed them in. Then I installed a GPU in each riser. In my frame, as seen in Figure 4, I am using only 4 GPUs. I could have added a fifth GPU riser space but then if I were to upgrade the GPUs to bigger ones, there would be no space for airflow. However, you could design yours better than what I did.
Now follow the documentation of the EVGA power supply and the GPU risers, or Youtube videos, and connect the power cables correctly to the GPU cards, the GPU risers and to the rest of the system.
 Figure 4. Top view after the GPUs have been installed
Figure 4. Top view after the GPUs have been installed
Now connect the riser end to the PCI-E slot of the HP Z840 server as shown in Figure 5. Here I installed my fifth GPU in one of the PCI-E x16 slots so that the computer could display something. In general, GPU risers do not work well with displays. The risers I chose were not being recognized by the BIOS/UEFI for display purposes.
 Figure 5. Inside view of the server where the PCI-E connections are made
Figure 5. Inside view of the server where the PCI-E connections are made
Everything is connected now. I then built a small front-facing tower so that I could attach the 7” HDMI screen to the front of the GPU rack as shown in Figure 6. The HDMI cable from this screen connects to the GPU that is inside the computer. The screen also has a touchscreen-and-power USB-C cable, which I connected to a USB-3 port on the computer.
 Figure 6. HDMI screen installed
Figure 6. HDMI screen installed
LINUX AND DRIVERS
I used Kali Linux on the HP Z840 as it works out of the box, but you can also use Ubuntu 22.04 LTS, if your purpose is something else besides password cracking. Installing Kali Linux follows standard procedure as described here.
Once you have installed Kali Linux, download the appropriate NVIDIA Drivers from https://www.nvidia.com/Download/index.aspx?lang=en-us. Select the correct combination in the form and download the driver file on to the computer. You will need a modern browser like Firefox or Google Chrome to do this. I recommend doing this directly on the computer you are setting up.
The form fields for the GTX 1650 are shown in Figure 7. Once you hit the Search button on the form you will get a file that is most recent from NVIDIA. As of this document, I got the file NVIDIA-Linux-x86_64-535.146.02.run, which means that the NVIDIA driver version is 535.146.02. I then run this file as root
as below, and follow the prompts to install everything. Then I install CUDA SDK from here
root$ ./NVIDIA-Linux-x86_64-535.146.02.run
## once completed, install CUDA
root$ wget https://developer.download.nvidia.com/compute/cuda/12.3.2/local_installers/cuda_12.3.2_545.23.08_linux.runsudo sh cuda_12.3.2_545.23.08_linux.run
root$ sh cuda_12.3.2_545.23.08_linux.run
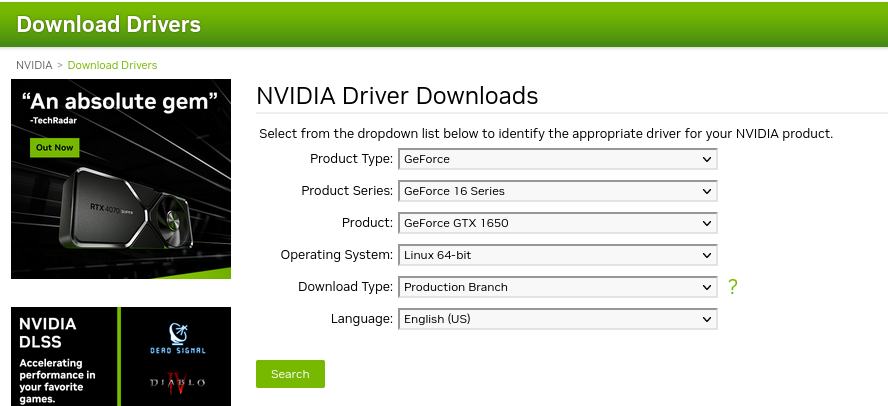 Figure 7. NVIDIA Driver form fields for GTX 1650
Figure 7. NVIDIA Driver form fields for GTX 1650
Once everything is installed, reboot the system and make sure it boots up so that you can view the HDMI screen showing the Kali Linux desktop as seen in Figure 8. You can also play some Youtube videos or videos using the VLC media player to see if everything is working as seen in Figure 9.
 Figure 8. Kali Linux setup completed
Figure 8. Kali Linux setup completed
 Figure 9. Video rendering test from Youtube
Figure 9. Video rendering test from Youtube
DEVICEQUERY
Next we run deviceQuery from the CUDA SDK to make sure that the GPUs are detected and we see the output showing 5 GPUs detected.
$ /usr/local/cuda/extras/demo_suite/deviceQuery
./deviceQuery Starting...
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 5 CUDA Capable device(s)
Device 0: "NVIDIA GeForce GTX 1650"
CUDA Driver Version / Runtime Version 12.2 / 12.2
CUDA Capability Major/Minor version number: 7.5
Total amount of global memory: 3904 MBytes (4093509632 bytes)
(14) Multiprocessors, ( 64) CUDA Cores/MP: 896 CUDA Cores
GPU Max Clock rate: 1590 MHz (1.59 GHz)
Memory Clock rate: 6001 Mhz
Memory Bus Width: 128-bit
L2 Cache Size: 1048576 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)
Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 1024
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 3 copy engine(s)
Run time limit on kernels: Yes
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
Device supports Unified Addressing (UVA): Yes
Device supports Compute Preemption: Yes
Supports Cooperative Kernel Launch: Yes
Supports MultiDevice Co-op Kernel Launch: Yes
Device PCI Domain ID / Bus ID / location ID: 0 / 2 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
Device 1: "NVIDIA GeForce GTX 1650"
CUDA Driver Version / Runtime Version 12.2 / 12.2
CUDA Capability Major/Minor version number: 7.5
Total amount of global memory: 3902 MBytes (4091150336 bytes)
(14) Multiprocessors, ( 64) CUDA Cores/MP: 896 CUDA Cores
GPU Max Clock rate: 1590 MHz (1.59 GHz)
Memory Clock rate: 6001 Mhz
Memory Bus Width: 128-bit
L2 Cache Size: 1048576 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)
Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 1024
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 3 copy engine(s)
Run time limit on kernels: Yes
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
Device supports Unified Addressing (UVA): Yes
Device supports Compute Preemption: Yes
Supports Cooperative Kernel Launch: Yes
Supports MultiDevice Co-op Kernel Launch: Yes
Device PCI Domain ID / Bus ID / location ID: 0 / 3 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
Device 2: "NVIDIA GeForce GTX 1650"
CUDA Driver Version / Runtime Version 12.2 / 12.2
CUDA Capability Major/Minor version number: 7.5
Total amount of global memory: 3904 MBytes (4093509632 bytes)
(14) Multiprocessors, ( 64) CUDA Cores/MP: 896 CUDA Cores
GPU Max Clock rate: 1590 MHz (1.59 GHz)
Memory Clock rate: 6001 Mhz
Memory Bus Width: 128-bit
L2 Cache Size: 1048576 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)
Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 1024
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 3 copy engine(s)
Run time limit on kernels: Yes
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
Device supports Unified Addressing (UVA): Yes
Device supports Compute Preemption: Yes
Supports Cooperative Kernel Launch: Yes
Supports MultiDevice Co-op Kernel Launch: Yes
Device PCI Domain ID / Bus ID / location ID: 0 / 4 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
Device 3: "NVIDIA GeForce GTX 1650"
CUDA Driver Version / Runtime Version 12.2 / 12.2
CUDA Capability Major/Minor version number: 7.5
Total amount of global memory: 3904 MBytes (4093509632 bytes)
(14) Multiprocessors, ( 64) CUDA Cores/MP: 896 CUDA Cores
GPU Max Clock rate: 1590 MHz (1.59 GHz)
Memory Clock rate: 6001 Mhz
Memory Bus Width: 128-bit
L2 Cache Size: 1048576 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)
Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 1024
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 3 copy engine(s)
Run time limit on kernels: Yes
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
Device supports Unified Addressing (UVA): Yes
Device supports Compute Preemption: Yes
Supports Cooperative Kernel Launch: Yes
Supports MultiDevice Co-op Kernel Launch: Yes
Device PCI Domain ID / Bus ID / location ID: 0 / 132 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
Device 4: "NVIDIA GeForce GTX 1650"
CUDA Driver Version / Runtime Version 12.2 / 12.2
CUDA Capability Major/Minor version number: 7.5
Total amount of global memory: 3904 MBytes (4093509632 bytes)
(14) Multiprocessors, ( 64) CUDA Cores/MP: 896 CUDA Cores
GPU Max Clock rate: 1590 MHz (1.59 GHz)
Memory Clock rate: 6001 Mhz
Memory Bus Width: 128-bit
L2 Cache Size: 1048576 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)
Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 1024
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 3 copy engine(s)
Run time limit on kernels: Yes
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
Device supports Unified Addressing (UVA): Yes
Device supports Compute Preemption: Yes
Supports Cooperative Kernel Launch: Yes
Supports MultiDevice Co-op Kernel Launch: Yes
Device PCI Domain ID / Bus ID / location ID: 0 / 133 / 0
Compute Mode:
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 12.2, CUDA Runtime Version = 12.2, NumDevs = 5, Device0 = NVIDIA GeForce GTX 1650, Device1 = NVIDIA GeForce GTX 1650, Device2 = NVIDIA GeForce GTX 1650, Device3 = NVIDIA GeForce GTX 1650, Device4 = NVIDIA GeForce GTX 1650
Result = PASS
NVTOP
I also installed NVTOP which is available on Kali Linux as the package nvtop or you can install the latest from Github. Running this shows the usage of the GPUs when you run the hashcat benchmark below.
HASHCAT
Install the package hashcat and run the benchmark as below, and you can view my system’s performance in the attached logs.
$ hashcat -b
hashcat (v6.2.6) starting in benchmark mode
Benchmarking uses hand-optimized kernel code by default.
You can use it in your cracking session by setting the -O option.
Note: Using optimized kernel code limits the maximum supported password length.
To disable the optimized kernel code in benchmark mode, use the -w option.
* Device #1: WARNING! Kernel exec timeout is not disabled.
This may cause "CL_OUT_OF_RESOURCES" or related errors.
To disable the timeout, see: https://hashcat.net/q/timeoutpatch
* Device #2: WARNING! Kernel exec timeout is not disabled.
This may cause "CL_OUT_OF_RESOURCES" or related errors.
To disable the timeout, see: https://hashcat.net/q/timeoutpatch
* Device #3: WARNING! Kernel exec timeout is not disabled.
This may cause "CL_OUT_OF_RESOURCES" or related errors.
To disable the timeout, see: https://hashcat.net/q/timeoutpatch
* Device #4: WARNING! Kernel exec timeout is not disabled.
This may cause "CL_OUT_OF_RESOURCES" or related errors.
To disable the timeout, see: https://hashcat.net/q/timeoutpatch
* Device #5: WARNING! Kernel exec timeout is not disabled.
This may cause "CL_OUT_OF_RESOURCES" or related errors.
To disable the timeout, see: https://hashcat.net/q/timeoutpatch
* Device #6: WARNING! Kernel exec timeout is not disabled.
This may cause "CL_OUT_OF_RESOURCES" or related errors.
To disable the timeout, see: https://hashcat.net/q/timeoutpatch
* Device #7: WARNING! Kernel exec timeout is not disabled.
This may cause "CL_OUT_OF_RESOURCES" or related errors.
To disable the timeout, see: https://hashcat.net/q/timeoutpatch
* Device #8: WARNING! Kernel exec timeout is not disabled.
This may cause "CL_OUT_OF_RESOURCES" or related errors.
To disable the timeout, see: https://hashcat.net/q/timeoutpatch
* Device #9: WARNING! Kernel exec timeout is not disabled.
This may cause "CL_OUT_OF_RESOURCES" or related errors.
To disable the timeout, see: https://hashcat.net/q/timeoutpatch
* Device #10: WARNING! Kernel exec timeout is not disabled.
This may cause "CL_OUT_OF_RESOURCES" or related errors.
To disable the timeout, see: https://hashcat.net/q/timeoutpatch
CUDA API (CUDA 12.2)
====================
* Device #1: NVIDIA GeForce GTX 1650, 3845/3903 MB, 14MCU
* Device #2: NVIDIA GeForce GTX 1650, 3813/3901 MB, 14MCU
* Device #3: NVIDIA GeForce GTX 1650, 3845/3903 MB, 14MCU
* Device #4: NVIDIA GeForce GTX 1650, 3845/3903 MB, 14MCU
* Device #5: NVIDIA GeForce GTX 1650, 3845/3903 MB, 14MCU
OpenCL API (OpenCL 3.0 CUDA 12.2.135) - Platform #1 [NVIDIA Corporation]
========================================================================
* Device #6: NVIDIA GeForce GTX 1650, skipped
* Device #7: NVIDIA GeForce GTX 1650, skipped
* Device #8: NVIDIA GeForce GTX 1650, skipped
* Device #9: NVIDIA GeForce GTX 1650, skipped
* Device #10: NVIDIA GeForce GTX 1650, skipped
OpenCL API (OpenCL 3.0 PoCL 4.0+debian Linux, None+Asserts, RELOC, SPIR, LLVM 15.0.7, SLEEF, DISTRO, POCL_DEBUG) - Platform #2 [The pocl project]
==================================================================================================================================================
* Device #11: cpu-haswell-Intel(R) Xeon(R) CPU E5-2680 v4 @ 2.40GHz, skipped
Benchmark relevant options:
===========================
* --optimized-kernel-enable
-------------------
* Hash-Mode 0 (MD5)
-------------------
Speed.#1.........: 11808.7 MH/s (78.33ms) @ Accel:1024 Loops:1024 Thr:64 Vec:8
Speed.#2.........: 11813.5 MH/s (78.31ms) @ Accel:1024 Loops:1024 Thr:64 Vec:8
Speed.#3.........: 11552.1 MH/s (80.09ms) @ Accel:1024 Loops:1024 Thr:64 Vec:8
Speed.#4.........: 11421.3 MH/s (80.83ms) @ Accel:1024 Loops:1024 Thr:64 Vec:8
Speed.#5.........: 11804.3 MH/s (78.38ms) @ Accel:1024 Loops:1024 Thr:64 Vec:8
Speed.#*.........: 58399.9 MH/s
----------------------
* Hash-Mode 100 (SHA1)
----------------------
Speed.#1.........: 3749.9 MH/s (62.10ms) @ Accel:512 Loops:1024 Thr:32 Vec:1
Speed.#2.........: 3751.1 MH/s (62.12ms) @ Accel:512 Loops:1024 Thr:32 Vec:1
Speed.#3.........: 3681.0 MH/s (63.25ms) @ Accel:512 Loops:1024 Thr:32 Vec:1
Speed.#4.........: 3633.8 MH/s (63.93ms) @ Accel:512 Loops:1024 Thr:32 Vec:1
Speed.#5.........: 3739.0 MH/s (62.21ms) @ Accel:512 Loops:1024 Thr:32 Vec:1
Speed.#*.........: 18554.8 MH/s
---------------------------
* Hash-Mode 1400 (SHA2-256)
---------------------------
Speed.#1.........: 1614.7 MH/s (72.23ms) @ Accel:16 Loops:1024 Thr:512 Vec:1
Speed.#2.........: 1610.3 MH/s (72.33ms) @ Accel:16 Loops:1024 Thr:512 Vec:1
Speed.#3.........: 1583.4 MH/s (73.66ms) @ Accel:16 Loops:1024 Thr:512 Vec:1
Speed.#4.........: 1570.4 MH/s (74.30ms) @ Accel:16 Loops:1024 Thr:512 Vec:1
Speed.#5.........: 1611.5 MH/s (72.38ms) @ Accel:16 Loops:1024 Thr:512 Vec:1
Speed.#*.........: 7990.3 MH/s
---------------------------
* Hash-Mode 1700 (SHA2-512)
---------------------------
Speed.#1.........: 538.1 MH/s (54.10ms) @ Accel:8 Loops:1024 Thr:256 Vec:1
Speed.#2.........: 537.2 MH/s (54.13ms) @ Accel:8 Loops:1024 Thr:256 Vec:1
Speed.#3.........: 527.9 MH/s (55.21ms) @ Accel:8 Loops:1024 Thr:256 Vec:1
Speed.#4.........: 523.7 MH/s (55.62ms) @ Accel:8 Loops:1024 Thr:256 Vec:1
Speed.#5.........: 537.5 MH/s (54.21ms) @ Accel:8 Loops:1024 Thr:256 Vec:1
Speed.#*.........: 2664.3 MH/s
-------------------------------------------------------------
* Hash-Mode 22000 (WPA-PBKDF2-PMKID+EAPOL) [Iterations: 4095]
-------------------------------------------------------------
Speed.#1.........: 189.2 kH/s (74.58ms) @ Accel:8 Loops:1024 Thr:512 Vec:1
Speed.#2.........: 189.0 kH/s (74.63ms) @ Accel:8 Loops:1024 Thr:512 Vec:1
Speed.#3.........: 185.9 kH/s (75.92ms) @ Accel:8 Loops:1024 Thr:512 Vec:1
Speed.#4.........: 177.1 kH/s (77.81ms) @ Accel:8 Loops:1024 Thr:512 Vec:1
Speed.#5.........: 188.4 kH/s (74.92ms) @ Accel:8 Loops:1024 Thr:512 Vec:1
Speed.#*.........: 929.6 kH/s
-----------------------
* Hash-Mode 1000 (NTLM)
-----------------------
Speed.#1.........: 20800.7 MH/s (87.84ms) @ Accel:512 Loops:1024 Thr:256 Vec:8
Speed.#2.........: 20805.9 MH/s (87.82ms) @ Accel:512 Loops:1024 Thr:256 Vec:8
Speed.#3.........: 20382.5 MH/s (89.59ms) @ Accel:512 Loops:1024 Thr:256 Vec:8
Speed.#4.........: 20180.9 MH/s (90.34ms) @ Accel:512 Loops:1024 Thr:256 Vec:8
Speed.#5.........: 20803.1 MH/s (87.82ms) @ Accel:512 Loops:1024 Thr:256 Vec:8
Speed.#*.........: 103.0 GH/s
---------------------
* Hash-Mode 3000 (LM)
---------------------
Speed.#1.........: 10825.9 MH/s (85.43ms) @ Accel:512 Loops:1024 Thr:128 Vec:1
Speed.#2.........: 10823.1 MH/s (85.46ms) @ Accel:512 Loops:1024 Thr:128 Vec:1
Speed.#3.........: 10616.0 MH/s (86.96ms) @ Accel:512 Loops:1024 Thr:128 Vec:1
Speed.#4.........: 10510.2 MH/s (87.80ms) @ Accel:512 Loops:1024 Thr:128 Vec:1
Speed.#5.........: 10826.2 MH/s (85.42ms) @ Accel:512 Loops:1024 Thr:128 Vec:1
Speed.#*.........: 53601.4 MH/s
--------------------------------------------
* Hash-Mode 5500 (NetNTLMv1 / NetNTLMv1+ESS)
--------------------------------------------
Speed.#1.........: 11111.5 MH/s (82.20ms) @ Accel:512 Loops:512 Thr:256 Vec:2
Speed.#2.........: 11116.5 MH/s (82.14ms) @ Accel:512 Loops:512 Thr:256 Vec:2
Speed.#3.........: 10913.1 MH/s (83.61ms) @ Accel:512 Loops:512 Thr:256 Vec:2
Speed.#4.........: 10768.1 MH/s (84.59ms) @ Accel:512 Loops:512 Thr:256 Vec:2
Speed.#5.........: 11112.8 MH/s (82.20ms) @ Accel:512 Loops:512 Thr:256 Vec:2
Speed.#*.........: 55022.1 MH/s
----------------------------
* Hash-Mode 5600 (NetNTLMv2)
----------------------------
Speed.#1.........: 828.3 MH/s (70.45ms) @ Accel:8 Loops:1024 Thr:512 Vec:1
Speed.#2.........: 828.0 MH/s (70.49ms) @ Accel:8 Loops:1024 Thr:512 Vec:1
Speed.#3.........: 813.1 MH/s (71.75ms) @ Accel:8 Loops:1024 Thr:512 Vec:1
Speed.#4.........: 804.0 MH/s (72.44ms) @ Accel:8 Loops:1024 Thr:512 Vec:1
Speed.#5.........: 825.2 MH/s (70.69ms) @ Accel:8 Loops:1024 Thr:512 Vec:1
Speed.#*.........: 4098.5 MH/s
--------------------------------------------------------
* Hash-Mode 1500 (descrypt, DES (Unix), Traditional DES)
--------------------------------------------------------
Speed.#1.........: 440.7 MH/s (66.17ms) @ Accel:16 Loops:1024 Thr:128 Vec:1
Speed.#2.........: 440.4 MH/s (66.23ms) @ Accel:16 Loops:1024 Thr:128 Vec:1
Speed.#3.........: 432.9 MH/s (67.35ms) @ Accel:16 Loops:1024 Thr:128 Vec:1
Speed.#4.........: 428.1 MH/s (67.97ms) @ Accel:16 Loops:1024 Thr:128 Vec:1
Speed.#5.........: 439.6 MH/s (66.35ms) @ Accel:16 Loops:1024 Thr:128 Vec:1
Speed.#*.........: 2181.7 MH/s
------------------------------------------------------------------------------
* Hash-Mode 500 (md5crypt, MD5 (Unix), Cisco-IOS $1$ (MD5)) [Iterations: 1000]
------------------------------------------------------------------------------
Speed.#1.........: 4093.2 kH/s (87.68ms) @ Accel:32 Loops:1000 Thr:1024 Vec:1
Speed.#2.........: 3910.5 kH/s (87.44ms) @ Accel:32 Loops:1000 Thr:1024 Vec:1
Speed.#3.........: 4043.0 kH/s (88.95ms) @ Accel:32 Loops:1000 Thr:1024 Vec:1
Speed.#4.........: 3997.3 kH/s (90.13ms) @ Accel:32 Loops:1000 Thr:1024 Vec:1
Speed.#5.........: 4089.5 kH/s (87.87ms) @ Accel:32 Loops:1000 Thr:1024 Vec:1
Speed.#*.........: 20133.4 kH/s
----------------------------------------------------------------
* Hash-Mode 3200 (bcrypt $2*$, Blowfish (Unix)) [Iterations: 32]
----------------------------------------------------------------
Speed.#1.........: 12829 H/s (67.59ms) @ Accel:4 Loops:32 Thr:16 Vec:1
Speed.#2.........: 12891 H/s (67.11ms) @ Accel:4 Loops:32 Thr:16 Vec:1
Speed.#3.........: 11677 H/s (69.25ms) @ Accel:4 Loops:32 Thr:16 Vec:1
Speed.#4.........: 12521 H/s (69.24ms) @ Accel:4 Loops:32 Thr:16 Vec:1
Speed.#5.........: 12810 H/s (67.59ms) @ Accel:4 Loops:32 Thr:16 Vec:1
Speed.#*.........: 62728 H/s
--------------------------------------------------------------------
* Hash-Mode 1800 (sha512crypt $6$, SHA512 (Unix)) [Iterations: 5000]
--------------------------------------------------------------------
Speed.#1.........: 85690 H/s (75.06ms) @ Accel:4096 Loops:128 Thr:64 Vec:1
Speed.#2.........: 85606 H/s (75.29ms) @ Accel:4096 Loops:128 Thr:64 Vec:1
Speed.#3.........: 84640 H/s (76.16ms) @ Accel:4096 Loops:128 Thr:64 Vec:1
Speed.#4.........: 83321 H/s (77.38ms) @ Accel:4096 Loops:128 Thr:64 Vec:1
Speed.#5.........: 85921 H/s (75.00ms) @ Accel:4096 Loops:128 Thr:64 Vec:1
Speed.#*.........: 425.2 kH/s
--------------------------------------------------------
* Hash-Mode 7500 (Kerberos 5, etype 23, AS-REQ Pre-Auth)
--------------------------------------------------------
Speed.#1.........: 208.8 MH/s (69.80ms) @ Accel:256 Loops:128 Thr:32 Vec:1
Speed.#2.........: 209.7 MH/s (69.49ms) @ Accel:256 Loops:128 Thr:32 Vec:1
Speed.#3.........: 204.2 MH/s (71.37ms) @ Accel:256 Loops:128 Thr:32 Vec:1
Speed.#4.........: 204.0 MH/s (71.49ms) @ Accel:256 Loops:128 Thr:32 Vec:1
Speed.#5.........: 209.4 MH/s (69.60ms) @ Accel:256 Loops:128 Thr:32 Vec:1
Speed.#*.........: 1036.2 MH/s
-------------------------------------------------
* Hash-Mode 13100 (Kerberos 5, etype 23, TGS-REP)
-------------------------------------------------
Speed.#1.........: 202.1 MH/s (72.17ms) @ Accel:256 Loops:128 Thr:32 Vec:1
Speed.#2.........: 202.4 MH/s (72.08ms) @ Accel:256 Loops:128 Thr:32 Vec:1
Speed.#3.........: 197.1 MH/s (73.99ms) @ Accel:256 Loops:128 Thr:32 Vec:1
Speed.#4.........: 197.2 MH/s (73.94ms) @ Accel:256 Loops:128 Thr:32 Vec:1
Speed.#5.........: 201.8 MH/s (72.25ms) @ Accel:256 Loops:128 Thr:32 Vec:1
Speed.#*.........: 1000.6 MH/s
---------------------------------------------------------------------------------
* Hash-Mode 15300 (DPAPI masterkey file v1 (context 1 and 2)) [Iterations: 23999]
---------------------------------------------------------------------------------
Speed.#1.........: 31835 H/s (74.54ms) @ Accel:8 Loops:1024 Thr:512 Vec:1
Speed.#2.........: 31408 H/s (75.23ms) @ Accel:8 Loops:1024 Thr:512 Vec:1
Speed.#3.........: 31288 H/s (75.85ms) @ Accel:8 Loops:1024 Thr:512 Vec:1
Speed.#4.........: 30821 H/s (77.01ms) @ Accel:8 Loops:1024 Thr:512 Vec:1
Speed.#5.........: 31726 H/s (74.81ms) @ Accel:8 Loops:1024 Thr:512 Vec:1
Speed.#*.........: 157.1 kH/s
---------------------------------------------------------------------------------
* Hash-Mode 15900 (DPAPI masterkey file v2 (context 1 and 2)) [Iterations: 12899]
---------------------------------------------------------------------------------
Speed.#1.........: 17781 H/s (61.59ms) @ Accel:64 Loops:512 Thr:32 Vec:1
Speed.#2.........: 17709 H/s (61.85ms) @ Accel:64 Loops:512 Thr:32 Vec:1
Speed.#3.........: 17372 H/s (62.83ms) @ Accel:64 Loops:512 Thr:32 Vec:1
Speed.#4.........: 17105 H/s (63.62ms) @ Accel:64 Loops:512 Thr:32 Vec:1
Speed.#5.........: 17745 H/s (61.74ms) @ Accel:64 Loops:512 Thr:32 Vec:1
Speed.#*.........: 87712 H/s
------------------------------------------------------------------
* Hash-Mode 7100 (macOS v10.8+ (PBKDF2-SHA512)) [Iterations: 1023]
------------------------------------------------------------------
Speed.#1.........: 221.8 kH/s (42.15ms) @ Accel:8 Loops:511 Thr:256 Vec:1
Speed.#2.........: 222.2 kH/s (41.96ms) @ Accel:8 Loops:511 Thr:256 Vec:1
Speed.#3.........: 219.4 kH/s (42.59ms) @ Accel:8 Loops:511 Thr:256 Vec:1
Speed.#4.........: 216.0 kH/s (43.27ms) @ Accel:8 Loops:511 Thr:256 Vec:1
Speed.#5.........: 204.1 kH/s (42.29ms) @ Accel:8 Loops:511 Thr:256 Vec:1
Speed.#*.........: 1083.5 kH/s
---------------------------------------------
* Hash-Mode 11600 (7-Zip) [Iterations: 16384]
---------------------------------------------
Speed.#1.........: 191.8 kH/s (70.55ms) @ Accel:32 Loops:4096 Thr:128 Vec:1
Speed.#2.........: 194.5 kH/s (70.53ms) @ Accel:32 Loops:4096 Thr:128 Vec:1
Speed.#3.........: 190.2 kH/s (71.31ms) @ Accel:32 Loops:4096 Thr:128 Vec:1
Speed.#4.........: 184.1 kH/s (72.41ms) @ Accel:32 Loops:4096 Thr:128 Vec:1
Speed.#5.........: 191.8 kH/s (70.52ms) @ Accel:32 Loops:4096 Thr:128 Vec:1
Speed.#*.........: 952.4 kH/s
------------------------------------------------
* Hash-Mode 12500 (RAR3-hp) [Iterations: 262144]
------------------------------------------------
Speed.#1.........: 26507 H/s (67.10ms) @ Accel:8 Loops:16384 Thr:256 Vec:1
Speed.#2.........: 26506 H/s (67.10ms) @ Accel:8 Loops:16384 Thr:256 Vec:1
Speed.#3.........: 26034 H/s (67.97ms) @ Accel:8 Loops:16384 Thr:256 Vec:1
Speed.#4.........: 25599 H/s (68.89ms) @ Accel:8 Loops:16384 Thr:256 Vec:1
Speed.#5.........: 26429 H/s (67.35ms) @ Accel:8 Loops:16384 Thr:256 Vec:1
Speed.#*.........: 131.1 kH/s
--------------------------------------------
* Hash-Mode 13000 (RAR5) [Iterations: 32799]
--------------------------------------------
Speed.#1.........: 19486 H/s (45.24ms) @ Accel:128 Loops:64 Thr:256 Vec:1
Speed.#2.........: 19522 H/s (45.22ms) @ Accel:128 Loops:64 Thr:256 Vec:1
Speed.#3.........: 19314 H/s (45.68ms) @ Accel:128 Loops:64 Thr:256 Vec:1
Speed.#4.........: 19022 H/s (46.29ms) @ Accel:128 Loops:64 Thr:256 Vec:1
Speed.#5.........: 19463 H/s (45.36ms) @ Accel:128 Loops:64 Thr:256 Vec:1
Speed.#*.........: 96805 H/s
--------------------------------------------------------------------------------
* Hash-Mode 6211 (TrueCrypt RIPEMD160 + XTS 512 bit (legacy)) [Iterations: 1999]
--------------------------------------------------------------------------------
Speed.#1.........: 141.0 kH/s (46.38ms) @ Accel:16 Loops:128 Thr:512 Vec:1
Speed.#2.........: 137.7 kH/s (46.81ms) @ Accel:16 Loops:128 Thr:512 Vec:1
Speed.#3.........: 138.7 kH/s (47.16ms) @ Accel:16 Loops:128 Thr:512 Vec:1
Speed.#4.........: 138.0 kH/s (47.43ms) @ Accel:16 Loops:128 Thr:512 Vec:1
Speed.#5.........: 140.6 kH/s (46.47ms) @ Accel:16 Loops:128 Thr:512 Vec:1
Speed.#*.........: 695.9 kH/s
-----------------------------------------------------------------------------------
* Hash-Mode 13400 (KeePass 1 (AES/Twofish) and KeePass 2 (AES)) [Iterations: 24569]
-----------------------------------------------------------------------------------
Speed.#1.........: 12017 H/s (49.40ms) @ Accel:2 Loops:1024 Thr:512 Vec:1
Speed.#2.........: 12113 H/s (49.00ms) @ Accel:2 Loops:1024 Thr:512 Vec:1
Speed.#3.........: 11750 H/s (50.25ms) @ Accel:2 Loops:1024 Thr:512 Vec:1
Speed.#4.........: 11827 H/s (50.20ms) @ Accel:2 Loops:1024 Thr:512 Vec:1
Speed.#5.........: 12016 H/s (49.41ms) @ Accel:2 Loops:1024 Thr:512 Vec:1
Speed.#*.........: 59723 H/s
----------------------------------------------------------------
* Hash-Mode 6800 (LastPass + LastPass sniffed) [Iterations: 499]
----------------------------------------------------------------
Speed.#1.........: 1214.1 kH/s (42.63ms) @ Accel:16 Loops:499 Thr:256 Vec:1
Speed.#2.........: 1202.6 kH/s (42.94ms) @ Accel:16 Loops:499 Thr:256 Vec:1
Speed.#3.........: 1195.4 kH/s (43.31ms) @ Accel:16 Loops:499 Thr:256 Vec:1
Speed.#4.........: 1014.7 kH/s (43.91ms) @ Accel:16 Loops:499 Thr:256 Vec:1
Speed.#5.........: 1207.9 kH/s (42.88ms) @ Accel:16 Loops:499 Thr:256 Vec:1
Speed.#*.........: 5834.8 kH/s
--------------------------------------------------------------------
* Hash-Mode 11300 (Bitcoin/Litecoin wallet.dat) [Iterations: 200459]
--------------------------------------------------------------------
Speed.#1.........: 2417 H/s (60.33ms) @ Accel:8 Loops:1024 Thr:256 Vec:1
Speed.#2.........: 2404 H/s (60.66ms) @ Accel:8 Loops:1024 Thr:256 Vec:1
Speed.#3.........: 2377 H/s (61.33ms) @ Accel:8 Loops:1024 Thr:256 Vec:1
Speed.#4.........: 2340 H/s (62.18ms) @ Accel:8 Loops:1024 Thr:256 Vec:1
Speed.#5.........: 2410 H/s (60.52ms) @ Accel:8 Loops:1024 Thr:256 Vec:1
Speed.#*.........: 11947 H/s
Started: Sun Jan 14 19:46:24 2024
Stopped: Sun Jan 14 19:51:23 2024
As you can see that the hashcat benchmark for MD5 is pretty good for a budget GPU cluster. We get about 58000 MH/s for this cluster and for a similar but more modern GPU you get about 57000 MH/s - 67000 MH/s but for several hundreds of dollars more in expenses. Anyway, the way I see it for my use case, the budget way using multi-GPUs is the way to go.
An RTX 3080 benchmarks around 54000 MH/s for MD5. An RTX 3090 benchmarks around 65000 MH/s for MD5. An RTX 4090 benchmarks around 164.1 GH/s for MD5, which is just phenomenal and can be probably worth buying if you can afford it.
NOTE: I have not run any benchmarks on the more expensive GPUs myself, they are all referencing benchmarks run by others on the internet, who may have different server hardware or different OSes or NVIDIA driver versions.
 Donate BITCOIN to 19hrWWw1dPvBE1wVPfCnH8LqnUwsT3NsHW.
Donate BITCOIN to 19hrWWw1dPvBE1wVPfCnH8LqnUwsT3NsHW.
